Kafka is an open source software which provides a framework for storing, reading and analysing streaming data.
Being open source means that it is essentially free to use and has a large network of users and developers who contribute towards updates, new features and offering support for new users.
Kafka is designed to be run in a “distributed” environment, which means that rather than sitting on one user’s computer, it runs across several (or many) servers, leveraging the additional processing power and storage capacity that this brings.
Kafka was originally created at LinkedIn, where it played a part in analysing the connections between their millions of professional users in order to build networks between people. It was given open source status and passed to the Apache Foundation – which coordinates and oversees development of open source software – in 2011.
What is Kafka used for?
In order to stay competitive, businesses today rely increasingly on real-time data analysis allowing them to gain faster insights and quicker response times. Real-time insights allow businesses or organisations to make predictions about what they should stock, promote, or pull from the shelves, based on the most up-to-date information possible.
Traditionally, data has been processed and transmitted across networks in “batches”. This is down to limitations in the pipeline – the speed at which CPUs can handle the calculations involved in reading and transferring information, or at which sensors can detect data. As this interview points out, these “bottlenecks” in our ability to process data have existed since humans first began to record and exchange information in written records.
Due to its distributed nature and the streamlined way it manages incoming data, Kafka is capable of operating very quickly – large clusters can be capable of monitoring and reacting to millions of changes to a dataset every second. This means it becomes possible to start working with – and reacting to – streaming data in real-time.
Kafka was originally designed to track the behaviour of visitors to large, busy websites (such as LinkedIn). By analysing the clickstream data (how the user navigates the site and what functionality they use) of every session, a greater understanding of user behaviour is achievable. This makes it possible to predict which news articles, or products for sale, a visitor might be interested in.
Since then, Kafka has become widely used, and it is an integral part of the stack at Spotify, Netflix, Uber, Goldman Sachs, Paypal and CloudFlare, which all use it to process streaming data and understand customer, or system, behaviour. In fact, according to their website, one out of five Fortune 500 businesses uses Kafka to some extent.
One particular niche where Kafka has gained dominance is the travel industry, where its streaming capability makes it ideal for tracking booking details of millions of flights, package holidays and hotel vacancies worldwide.
How does Kafka work?
Apache takes information – which can be read from a huge number of data sources – and organises it into “topics”. As a very simple example, one of these data sources could be a transactional log where a grocery store records every sale.
Kafka would process this stream of information and make “topics” – which could be “number of apples sold”, or “number of sales between 1pm and 2pm” which could be analysed by anyone needing insights into the data.
This may sound similar to how a conventional database lets you store or sort information, but in the case of Kafka it would be suitable for a national chain of grocery stores processing thousands of apple sales every minute.
This is achieved using a function known as a Producer, which is an interface between applications (e.g. the software which is monitoring the grocery stores structured but unsorted transaction database) and the topics – Kafka’s own database of ordered, segmented data, known as the Kafka Topic Log.
Often this data stream will be used to fill data lakes such as Hadoop’s distributed databases or to feed real-time processing pipelines like Spark or Storm.
Another interface – known as the Consumer – enables topic logs to be read, and the information stored in them passed onto other applications which might need it – for example, the grocery store’s system for renewing depleted stock, or discarding out-of-date items.
When you put its components together with the other common elements of a Big Data analytics framework, Kafka works by forming the “central nervous system” that the data passes through input and capture applications, data processing engines and storage lakes.
Now that we know what Apache Kafka is, let’s move on to why it is so popular.
Hopefully this article serves to give an overview of how, where and why Kafka is used, and some of the factors which have supported its huge growth in popularity. If you want more in-depth details about how it works, as well as information on how to get started using it yourself, there are some great resources online:
Apache Kafka is an open source stream processing program that was developed by LinkedIn but is now under the Apache foundation. It is written in Scala and Java.
Kafka can really help you create real-time, robust applications in conjunction with any programming language like Java, Node etc.
In Simpler terms, Apache Kafka is a Message broker i.e. it helps transmit messages from one system to another – in real time, reliable manner. But that’s not all, Kafka can also work on streams of data and transform them (if required) using its stream API making it really helpful in a lot of use cases.
Why Kafka?
There are a lot of reasons for choosing Kafka as your message broker like replication, high performance, and fault tolerance. But what makes Kafka shine out are:
Kafka’s ability to scale without downtime
Kafka’s ability to work with high volumes of streams of data and provisions for transforming the aforementioned data, making it an ideal choice when working with big data
But before we dive down into the APIs that Kafka offer, it’s important that we first understand the terminologies associated with Kafka.
Topics
Kafka stores streams of similar records in categories called Topics. The closest analogy of a topic would be a table in a relational database. Example: User location data for multiple users can be part of the same topic.
Topics in Kafka are identified by the topic name.
Partitions
Records in topics are further divided across partitions. A topic can have ‘n’ number of partitions. The number of partitions that a topic should have needs to mentioned at the time of topic creation.
A large amount of thought needs to be put into deciding the number of partitions for a topic. Increasing the number of partitions for a topic improves the throughput but can also have some serious repercussion like — higher unavailability and an increased end-to-end latency.
A detailed description of how the number of partitions affects Kafka can be found here.
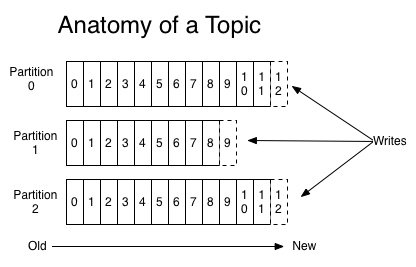
In the above diagram, the topic has 3 partitions: Partition 0, Partition 1 and Partition 2. The numbers written inside each partition denotes the offset of the message in that partition.
Offsets
Every message in a partition is assigned an integer value, called offset which uniquely identifies the message in the partition.
Within a partition a message with offset i is always processed before the message with offset i+1.
Kafka also stores the write offset for all the partitions for a topic, so that it knows where to insert the new record.
Producers
Producers publish data to the topic with the help of the topic name. It is the producer’s responsibility to decide which message will go to which partition.
If there is no key associated with the topic the messages gets load balanced between the partitions round robin algorithm. But it is also possible to functionally determine (using some key in the message or some other variable factor) the partition to which a record should go.
Consumers
Compared to Producers, Consumers are a little tricky to understand. Consumers subscribe to topics and acts on messages. Consumers generally label themselves under a group — consumer group.
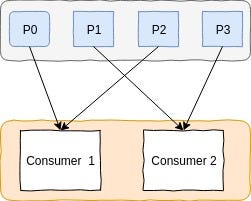
Messages that are published to a topic are sent to exactly one consumer instance within each subscribing consumer group i.e. consumers in a group never share a partition. This is to make sure that the same message doesn’t get processed twice and also guarantees that the order of records processed for a partition.
If all the consumer instances belong to the same consumer group then the records are load balanced across all consumers.
Kafka fairly distributes the total number of partitions across the consumers in the consumer group.
For example — Let’s say there is a topic which has 4 partitions(Pi) and there exists a consumer group (with 2 consumers) that is subscribed to this topic. Kafka now will try and divide the total partitions (4) across all the available consumers (2) i.e. each consumer will process the records of 2 partitions.
If there are more number of consumers than the number of partitions in a topic then one of the consumer will have to sit ideal.
If any new consumer joins the group, some of the partitions are reassigned to the new instance. Similarly, if an instance dies, its partitions are reassigned to other consumers in the group.
Brokers
We use Kafka as a cluster, which means that there are generally one or more servers that work together to fulfil the requests. These servers are called Kafka brokers or brokers.
I hope you found this blog helpful and that I was able to transfer my knowledge of Kafka to you.